


")
FileBrowser (Javascript, PHP, Smarty)
FileBrowser is no longer supported.
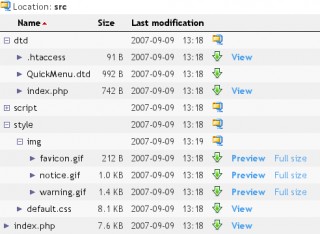
Určitě jste se někdy dostali do situace, že jste potřebovali na webu zveřejnit několik souborů ke stažení, prohlížení a tak... Nabízí se několik možností, jak to udělat. Pokud je souborů málo, můžete vytvořit webovou stránku a umístit na ni odkazy na soubory. Pokud je souborů více, můžete požádat Apache o automatické vytvoření indexu pro dostupné soubory.
Tato řešení jsou možná jednodušší pro vývojáře, ale z pohledu uživatele jsou poněkud těžkopádná. Projeví se to zejména, když je souborů hodně, nebo když jsou hluboko zanořené v adresářovém stromu. Rozhodl jsem se proto naprogramovat vlastní prohlížeč souborů (prozatím v režimu read-only) a tím je právě komponenta FileBrowser.
Stejně jako u komponenty QuickMenu jsem se při návrhu inspiroval filozofií KDE - snažil jsem se, aby uživatel docílil toho, co potřebuje, s minimálním počtem kliků a v nejkratším možném čase. Stejně jako na automatickém indexu Apache se soubory a složky zobrazují v tabulce, jsou tam také přibližně stejné sloupce a data v nich. Soubory a složky se dají řadit podle jednotlivých sloupců oběma směry. Řazení je vždy stavové (i při asynchronní komunikaci) a složky jsou vždy na začátku tabulky.
Rychlá odezva
První věcí, která je v komponentě FileBrowser navíc, je takový ten malý obrázek  , který se zobrazuje před každou složkou. Když na něj poprvé kliknete, složka se rozbalí velice rychle. Místo toho, aby se načítala znovu celá stránka, pošlou se ze serveru pouze data o konkrétní složce - v obchodní sféře je tato technika známá pod pojmem AJAX. Pokud složku opět sbalíte a kliknete na podruhé, složka se rozbalí ještě rychleji. Potřebná data jsou již totiž k dispozici na straně klienta, není proto nutné se serverem vůbec komunikovat.
, který se zobrazuje před každou složkou. Když na něj poprvé kliknete, složka se rozbalí velice rychle. Místo toho, aby se načítala znovu celá stránka, pošlou se ze serveru pouze data o konkrétní složce - v obchodní sféře je tato technika známá pod pojmem AJAX. Pokud složku opět sbalíte a kliknete na podruhé, složka se rozbalí ještě rychleji. Potřebná data jsou již totiž k dispozici na straně klienta, není proto nutné se serverem vůbec komunikovat.
Zajímá-li Vás, jak vypadají data, která chodí ze serveru během procházení, tady je ukázka. Je to plnohodnotný validní XHTML dokument, který však kromě dat o složce neobsahuje žádný balast. Výhoda XHTML spočívá v tom, že je spolehlivěji zpracovatelné parserem prohlížeče. Lze totiž předpokládat, že dokáže-li prohlížeč správně zobrazit XHTML dokument, pak dokáže zpracovat i jeho část pomocí objektů Javascriptu.
Náhledy obrázků
Pokud máte mezi soubory obrázky, může Vám FileBrowser zobrazit náhledy - a to hned dvěma způsoby. První způsob je, že na soubor kliknete, načte se nová stránka a na ní je zmenšenina obrázku. Druhý způsob je pohodlnější - stačí na jméno obrázku najet myší. Pokud se náhled zobrazuje poprvé, opět musí proběhnout asynchronní komunikace se serverem. Tentokrát je však řízena pouze prohlížečem a není potřeba vytvářet objekt XMLHttp.
Syntax highlighting
Pokud máte mezi soubory zdrojové kódy, můžete si zobrazit jejich syntaxi barevně zvýraznit stejně jako ve svém oblíbeném editoru. Opět stačí kliknout na jméno souboru. O zvýraznění syntaxe se nestará samotná komponenta FileBrowser - to by musela být mnohem složitější a musel by ji programovat někdo šikovnější. Komponenta FileBrowser používá obecný syntaktický zvýrazňovač GeSHi. Vlastně používá jen jeho malou část, lepší integraci GeSHi plánuji s příchodem jeho stabilní 2.x verze - rozhraní této verze pravděpodobně nebude zpětně kompatibilní.
Stahování složek
Poslední vymožeností komponenty FileBrowser je stahování celých složek. Můžete si ve stromu vybrat kteroukoliv složku a stáhnout ji včetně souborů a podsložek jako ZIP archiv - stačí kliknout na malý obrázek  . K zabalení složek a souborů používá komponenta rozšíření PHP pro práci s ZIP archivy.
. K zabalení složek a souborů používá komponenta rozšíření PHP pro práci s ZIP archivy.
Komprimování většího množství dat může trvat delší dobu a taky výrazně zatížit server. V současné verzi se velikost stahovaných dat žádným způsobem nehlídá, protože na webu žádná objemná data nemám.
Tested browsers
 Firefox 2, 3
Firefox 2, 3
 Opera 9.60 Beta
Opera 9.60 Beta
 Konqueror 3, 4
Konqueror 3, 4
 Internet Explorer 6, 7
Internet Explorer 6, 7


 FileBrowser.tpl
FileBrowser.tpl